
VR2020: Audio Design for Public Rooms (Part 1)
One of the challenges of creating social VR spaces is balancing the audio. There are tools and plugins for some game engines that can pre-compute approximations to realistic audio propagation in fixed environments (e.g., AudioKinetic's WWise), and experimental systems that can compute some simple effects in real-time (e.g., a quick search turned up https://github.com/Satrat/AR-Reverb, among others), but in general purpose sandbox environments like Hubs we can't (yet) realistically simulate the interactions between sound waves and a dynamically changing space. Walls and dividers, avatars and terrain, none of it affects sound propogation.
Part of the problem is that the simple structure of space is just the start: materials matter a lot. Once you define a mesh, there are many properties that affect how sound works in a space (are those walls hard and reflective, or padded with sound damping material? Is that a marble floor or a carpet?). Not to mention how sound travels between spaces (how thick is that wall? Does it block sound or act as a massive baffle, cutting off high frequencies and amplifying the base?). And how do we even think about the sound properties of dynamic media content that comes and goes (what are the sound properties of that image you placed in there? Do you want it to block what the speaker is saying, or not?). And even if we could do a super accurate simulation, is that really what we want? To be constrained to realistic simulation? Do you want to have to use a microphone, or yell, to talk to large crowds?
In Hubs, the situation is still fairly simple: audio is based on the Web Audio PannerNode, which gives you three different audio distance models for audio fall-off (linear, inverse, and exponential), which use a set of simple parameters to determine how sound falls off over distance. Without plugins and pre-computed audio simulations (akin to pre-baked lighting), this is how most 3D engines still work. The current Hubs default avatar audio settings use the inverse behavior with a reference distance of 1 meter, and a rolloff factor of 2. This results in audio that begins to fall off relatively close to the avatar, but does so gradually.
Audio for Small Groups in Different Situations
So, what settings should we use? What works for one use (a small group chatting close together), might be frustrating for another (one person giving a lecture to a group spread out over an interactive space). In the former, the group can arrange to be close enough that everyone sounds approximately the same volume; in the later case, people farther from the speaker may have trouble hearing.
Multiple small groups in one space pose a different problem, especially when each group has a central character speaking to that group. Now, we want the audio to be loud enough everyone in the group can hear it, but not overpower the audio in nearby groups.
When we experimented with running a small poster session for the ACM UIST 2019 conference in Mozilla Hubs, we used a room with the Hubs default audio settings. Hubs' default setting try to strike a balance between many use cases, so the audio from each avatar starts falling off relative close to the avatar and falls off gradually over distance. To deal with the gradual fall-off, we spaced the posters far apart, as seen here.
This worked reasonably well, but was still frustrating, with attendees complaining the noise from one poster was too loud near the other posters. At the same time, it was frustrating to have to get very close the poster-presenters to hear them clearly; it was almost impossible to stand far enough back to see the entire poster layout, and still hear the speaker.
For VR 2020, we wanted to pick audio settings for each of our public rooms to better account for their use. Roughly speaking, there were four classes of rooms:
- Poster rooms. We spread 144 posters across 36 rooms; with Hubs spaces limited to 2-25 people, this seemed like a good balance of having enough people in each space while allowing a lot of people to attend the poster session. Each room had four poster spaces, where each space had a speaker on one side (near their poster) and a (possibly large) group of people talking to them. The key need was having the audio in the space near the poster be fall off gradually, but then drop quickly so it is a low mumor near the other posters. There were no media elements in these rooms, just avatar audio.
- Demo rooms. Relatively small rooms, with media (videos) and avatars, but only one focal activity. Here, we wanted the media and avatar audio to carry a longer distance, and fall off more gradually. This would let visitors step back to have a conversation, but still hear the presenters and (assuming they stepped back far enough) not disturb other people too much (all avatars share one setting).
- Social spaces. We wanted people to be able to gather in slightly larger groups in each room than might be common in Hubs, since we anticipated conversations centered around a topic that many people would want to join in. Therefore, we wanted the sound to maintain full volume for a longer distance from each avatar than the Hubs default, and fall off faster than the default. We also wanted sound to carry more that the poster or presentation rooms, so the spaces felt busy and active.
- Video Watching rooms. One of the primary uses we originally had for Hubs was to co-watch the video streams coming into the space. Here, we wanted the media audio (from the video streams) to be relatively constant over a large area, then fall off rapidly. This way, all viewpoints with that area had equally good audio, but visitors could move outside that space to have a conversation. Conversely, we wanted the avatar audio to travel a much smaller distance, but also fall off very rapidly, so a group of visitors could separate themselves from other viewers and chat without distributing them.
- Presentation rooms. These were rooms designed by individual speakers to give a presentation. We supported speakers doing their presentations in a Hubs room, where it would be streamed to the video watching rooms and out to Twitch. There would not be visitors. Instead, we wanted the audio to carry quite far, so that the "camera person" filming the external view of the space would always hear the audio from the speaker and media at full volume.
To experiment with these different settings, I created an "Audio Settings Test RR" scene, with the same video set up with different audio settings so that I could play a video, and move away from it to see how the audio settings worked. Feel free to try it yourself (sorry about the RR). (aside: Hubs proved quite powerful here, since I could invite a few other people to try out the room as I changed the underlying scene, without really planning to do so in advance. All immersive experiences should be transparently multi-user!)

We found out pretty quickly we wanted settings very different than the defaults, both for media and avatars.
For avatars, the balance needed to be between wanting to hear clearly at a reasonable distance, where "reasonable" changes for each context. We also decided that we still wanted to have a sense of other avatars talking at a distance, at reduced volumes that avoided overwhelming the avatars talking nearby. For all cases, we needed to increate both the distance before fall-off, and the speed of fall-off.
There was some appeal to the rapid fall-off of the exponential model with high rolloff, but initial test users found it disconcerting to hear almost nothing from avatars in the same room. Using the default inverse model, but cranking the rolloff factor up, gave a better feel.
First Example: The Poster Rooms
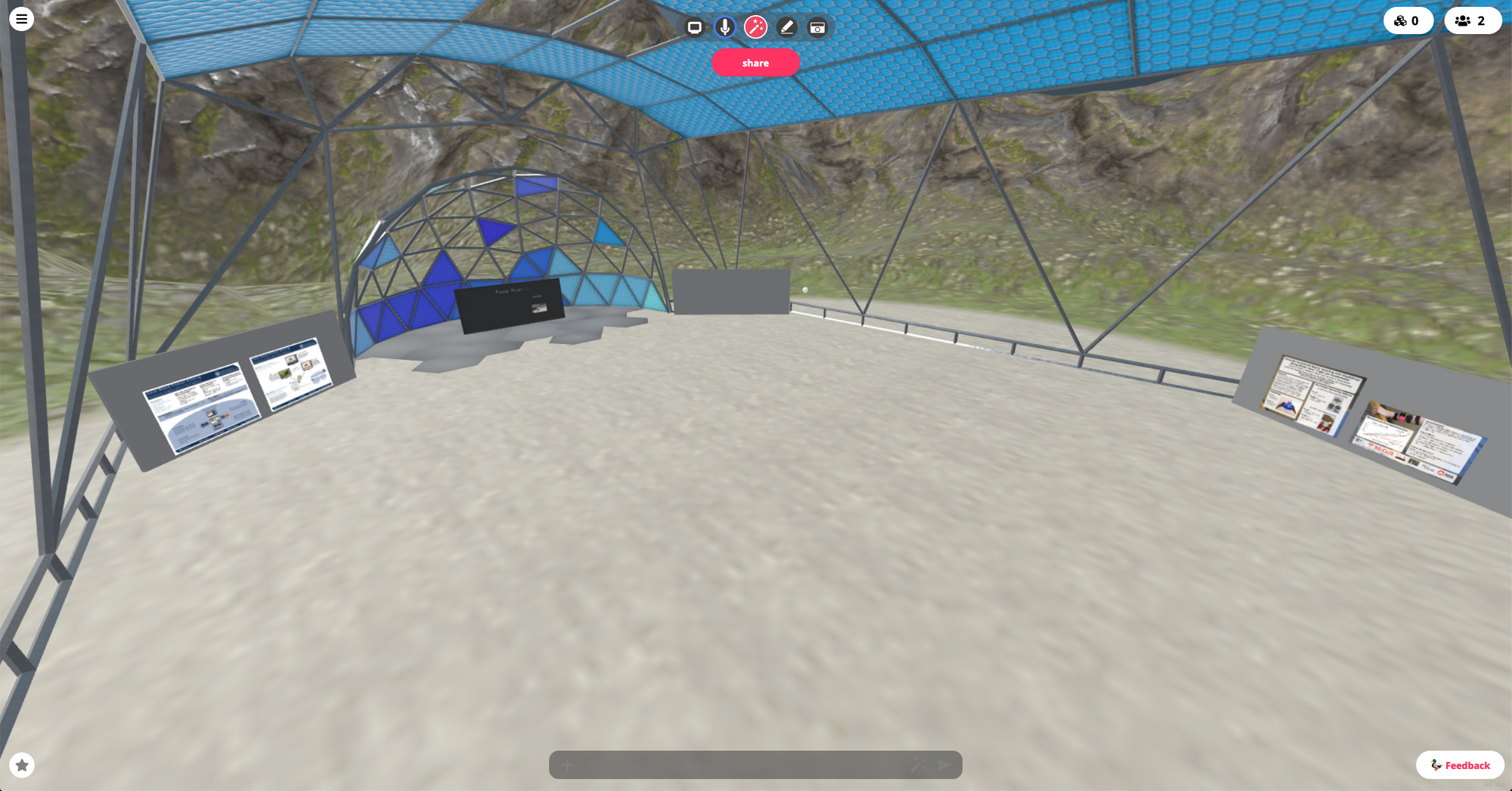
For poster rooms, we wanted to have the posters closer together that we did at UIST, so people could more easily move between them and the space would more cozy and less barren. Here's an image of a VR2020 poster room.

Looking at this room in the Spoke scene editor, each of the small squares on the floor is half a meter; the distance between the posters is about 15 meters. In the audio settings for the scene (on the lower right in the image below), the two parameters that mater for the inverse model are the Avatar Rolloff Factor and the Avatar Reference Distance, which we ended up setting to 10 and 4.
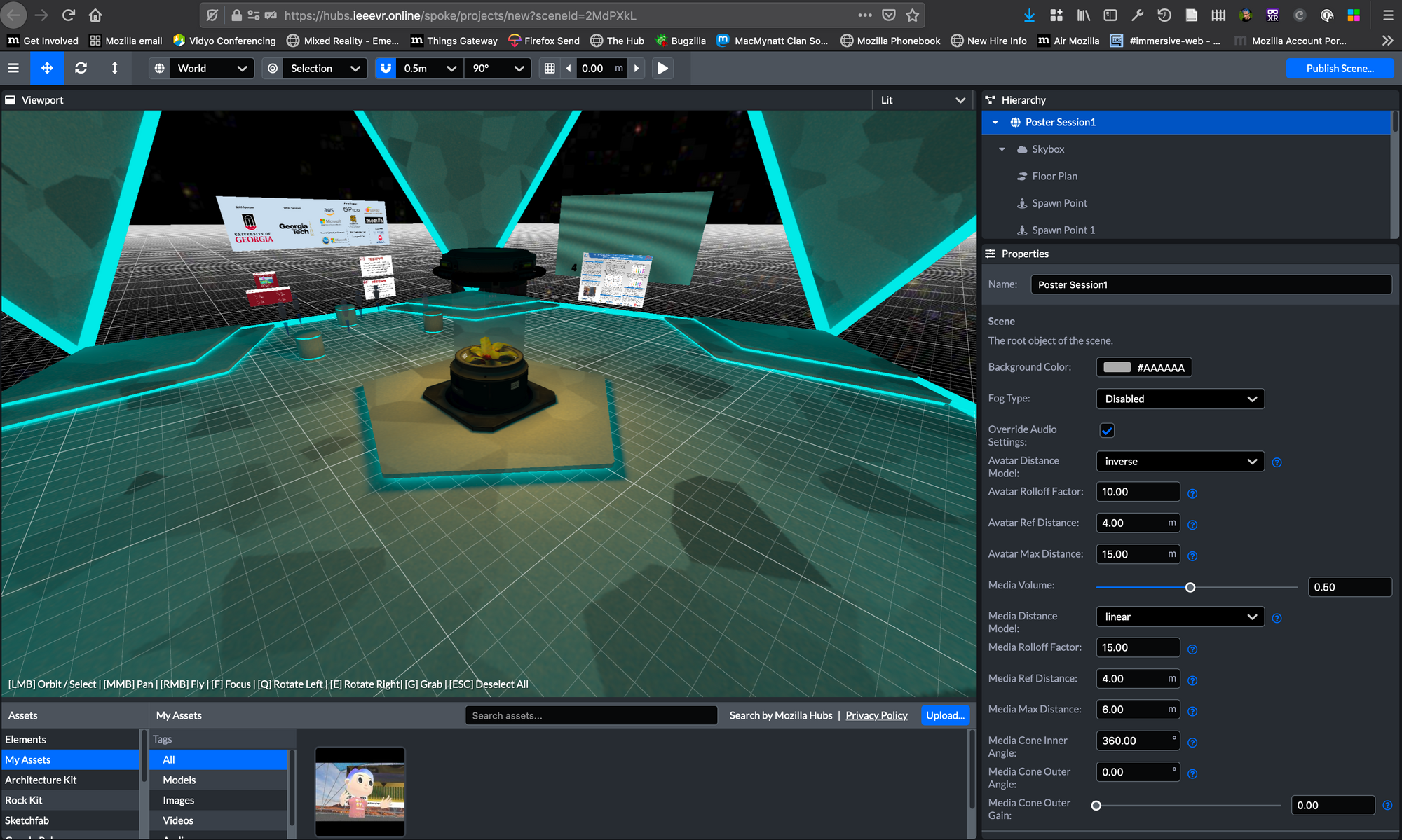
The result was that if two speakers stood on the sides of their posters nearest to each other (worst case), the audio from each would be clear for less than half the distance between them (roughly at the point it reaches the tip of the raises area between the posters), and then start to fall of rapidly. This was designed to give listerers in the room a good experience: they would only hear one of these two speakers clearly, and as they moved from one poster to another, the audio from one speaker would fall off before the audio from the other would pick up. It also meant that if a group of visitors stood near the entrance, or in the middle of the room, they could chat without overly disturbing the groups around the posters.
We think this design worked out pretty well, based on feedback. It could probably be tuned further, but given the hectic final days leading up to the conference, I'm pretty happy with the result. Feel free to try out this scene yourself (scene link is in the caption of the picture above) and perhaps even use it as the starting point for running your own poster session.
Next ...
In a future post, I'll discuss the analogous design issues with the other kinds of rooms we created, for those who are interested in the details of all the public rooms we created.