
Experimenting with Computer Vision in WebXR
(originally published on the Mozilla MR Blog, May 2018. Just in case Mozilla shuts down the blog after shutting down the team, I'm preserving the posts I wrote for the blog.)
Over the past few months, we’ve been experimenting with what it would take to enable efficient, usable computer vision in WebXR. We’ve implemented a simple set of APIs in our iOS WebXR Viewer and the webxr-polyfill to test these ideas, and created some examples demonstrating how these APIs would work in practice, from simple color detection to tracking black and white markers in 3D using a WebAssembly version of the OpenCV computer vision library.
The simplest example we built computes two values: the average luminance of all pixels in the image, and the RGB color of the pixels in the center of the screen. (Interestingly, since most cameras have auto-gain turned on, the average luminance is usually close to 0.5 in our tests.)

While seemingly trivial, even simple image analysis can be used in interesting ways, such detecting if a yellow post-it note is on the screen, or activating bombs to blow up zombies in an AR game students at Georgia Tech and the Savannah College of Art and Design made back in 2009.
Download the WebXR Viewer app and try a few samples, or use the sample code (available on github) as the starting point for your own explorations.
Computer Vision and WebXR
Many XR displays have cameras integrated into them, such the HTC Vive, Microsoft Hololens, and phones and tablets running ARKit and ARCore. WebXR can enable a wide range of cross platform applications that require non-standard tracking and sensing of the environment if it is possible to efficiently access video images from these cameras in Javascript, along with the properties of the camera such as it’s field of view and pose in the world.
Currently, XR platforms expose the pose (position and orientation) of the user’s display in the space around it. Some devices also track one or two controllers in the same space; others sense the structure of that space, either as full 3D meshes (on Windows MR and Hololens devices) or as planes (on ARKit and ARCore).
But AR applications, in particular, need to know more than just where they are in space; they also need to be able to sense and track “things” in the world. An AR application can only “augment” those things (people, images, or objects) that it knows about. Unfortunately, the various XR platforms will not be able to detect and track every possible thing an application might care about any time soon. Platforms like ARKit and ARCore are adding new sensing capabilities with each version, but those features are platform specific, preventing applications that rely on them from running everywhere.
Native applications can leverage SDKs like PTC’s Vuforia to detect and track images and objects. Lower level computer vision libraries like OpenCV let sophisticated developers create their own libraries for detecting and tracking things they care about. OpenCV can now be compiled into Web Assembly (a standard build target since December 2017) and run in a web page or Web Worker, opening the door to doing more sophisticated custom computer vision on the web.
Why Not Just Add Computer Vision Algorithms To the Browser?
Some of these algorithms will make it into the browsers over time, but a web standard like WebXR needs to expose a common subset of AR and VR capabilities that work on any platform, so that web apps written using the standard can reasonably expect to run everywhere. Each of the AR platforms supports a different set of sensing capabilities, and there is no reason to expect that every platform will support every possible form of sensing any time soon (if ever). There will continue to be new algorithms to sense and detect specific things in the environment, and being able to run them in every browser will let them be delivered to the widest audience.
Computer Vision On the Web
It’s currently possible to do simple computer vision on the web, by grabbing video frames from a device obtained from mediaDevices.getUserMedia(), but the limitations of current Web APIs make it difficult to implement sophisticated algorithms comparable to what is possible in native applications.
Three things need to be added to Web APIs to make them amenable to sophisticated computer vision.
The first is the most well known to programmers who have tried to do web-based CV:
Efficient, real-time access to video from the cameras attached to devices
To use mediaDevices.getUserMedia(), a programmer attaches the media device to a DOM video element, and renders from the video element into a canvas element to retrieve a video frame. The MediaStream Image Capture draft proposal is designed to make this more efficient, allowing developers to directly retrieve an ImageBitmap from a video stream using the grabFrame() method (it is currently only implemented in Chrome).
The second issue is that web APIs do not give enough information about the cameras themselves. Many computer vision algorithms require knowledge about the optical characteristics of the camera, so we need:
Knowledge about the intrinsic properties (including focal length, skew and principal point) of the cameras.
Current web standards haven’t exposed this information because most cameras attached to computers today do not make their intrinsic details available to the platform. A proposal for a MediaStream Capture Depth Stream Extension explored how to extend the Media Capture and Streams specification to support depth-only or combined depth+color streams. As part of that draft specification, the MediaTrackSettings dictionary was extended to include the intrinsic properties of the camera, including focal length, principal point and distortion coefficients.
Like some depth cameras, it is reasonable to assume that the precise details of the cameras on a WebXR device are available via the platform. For example, Hololens’ camera includes this information in metadata attached to each captured frame, and ARKit and ARCore provide camera intrinsics to developers.
Finally, beyond efficient access to camera data and the camera properties, WebXR devices know the pose of the device in some world coordinate system, which means the systems knows the pose of the camera when a video frame is captured (the extrinsic properties of the camera). This information needs to be made available to the developer (as described, again, in the Hololens’ documentation).
Therefore, the third requirement for doing computer vision on the web (in WebXR) is:
Knowledge about the extrinsic properties (pose relative to the head and world coordinate systems) of the cameras
Together, these three pieces of information would allow developers to do custom computer vision on the web, in a way that leverages and integrates with the WebXR APIs and underlying platforms. To demonstrate how this might work, we added a simple API to obtain this information from our WebXR Viewer iOS app and webxr-polyfill.
Computer Vision in the WebXR Viewer
The WebXR Viewer is based on ARKit, and runs by injecting information into Apple’s wkWebview, the same underlying iOS library that all web browsers on iOS use. (Apple restricts iOS web browsers from using any other web component in their applications, or from modifying the wkWebView.) Each time the app gets a video frame and the associated updates about real-world Anchors from ARKit, we inject all of this information into the wkWebview, which is then exposed to the programmer via the WebXR polyfill. This process is moderately expensive (the data needs to be converted into a Javascript command that is executed in the Webview, with the data being formatted as a JSON object).
A Note About Performance
To send in a large binary object like a frame of video into the wkWebView, it must first be encoded as a text string (using base64 encoding, in this case), and then decoded inside the Webview. As you can imagine, this is quite expensive to do every video frame, but it works surprisingly well as long as we downsample the video frame well below the full size provided by ARKit (e.g., on an iPhone X, the video frames are 1080p resolution, which is far too large). In each of the examples discussed here, you can see a graph of the “CV fps” (computer vision frames per second) in the upper right corner. In the WebXR Viewer, it’s often surprisingly low (less than 10 fps, or worse) even though the graphics are rendering at close to 60 frames per second. We suspect this is a combination of factors; partially the overhead of passing these huge strings into the Webview and then on into a Web Worker, and partially because ARKit is consuming a lot of the available processor cycles in the background.
The webxr-polyfill works in traditional browsers, and we implemented the computer vision extensions as well as we could in such browsers (using mediaDevices.getUserMedia() to retrieve low resolution video frames), mostly to simplify debugging. While the CV examples don’t work completely without the spatial tracking or camera intrinsics provided by ARKit, you can see from the two images below that they yield much higher CV frame rates than in the WebXR Viewer, typically running at the video frame rate of 60 frames per second (these images were captured in Mobile Safari on the same iPhone as the videos in this page). Efficient native implementations should yield even better results.


A second performance issue with the WebXR Viewer is that the video is being displayed in the native application and the web graphics are being rendered by a separate thread in the web view, without any synchronization between the Javascript thread and the native threads. The positive side of this is that the video is rendered very quickly; the negative side is that the two are not tightly aligned, so the graphics appear to swim relative to the video.
Neither of these problems will exist in a native implementation of this API, and while they distract a bit from the final result, we are able to experiment with how this might be presented to web programmers.
A Note About Privacy
Any web API that accesses the camera will need to obtain explicit user permission, just as current camera, microphone and geolocation APIs do. Hopefully, as WebXR is added to new browsers, we won’t end up with a sequence of popups users click through without reading, but to keep things simple in our implementation, we are explicitly asking for permission each time a web app request video frames.
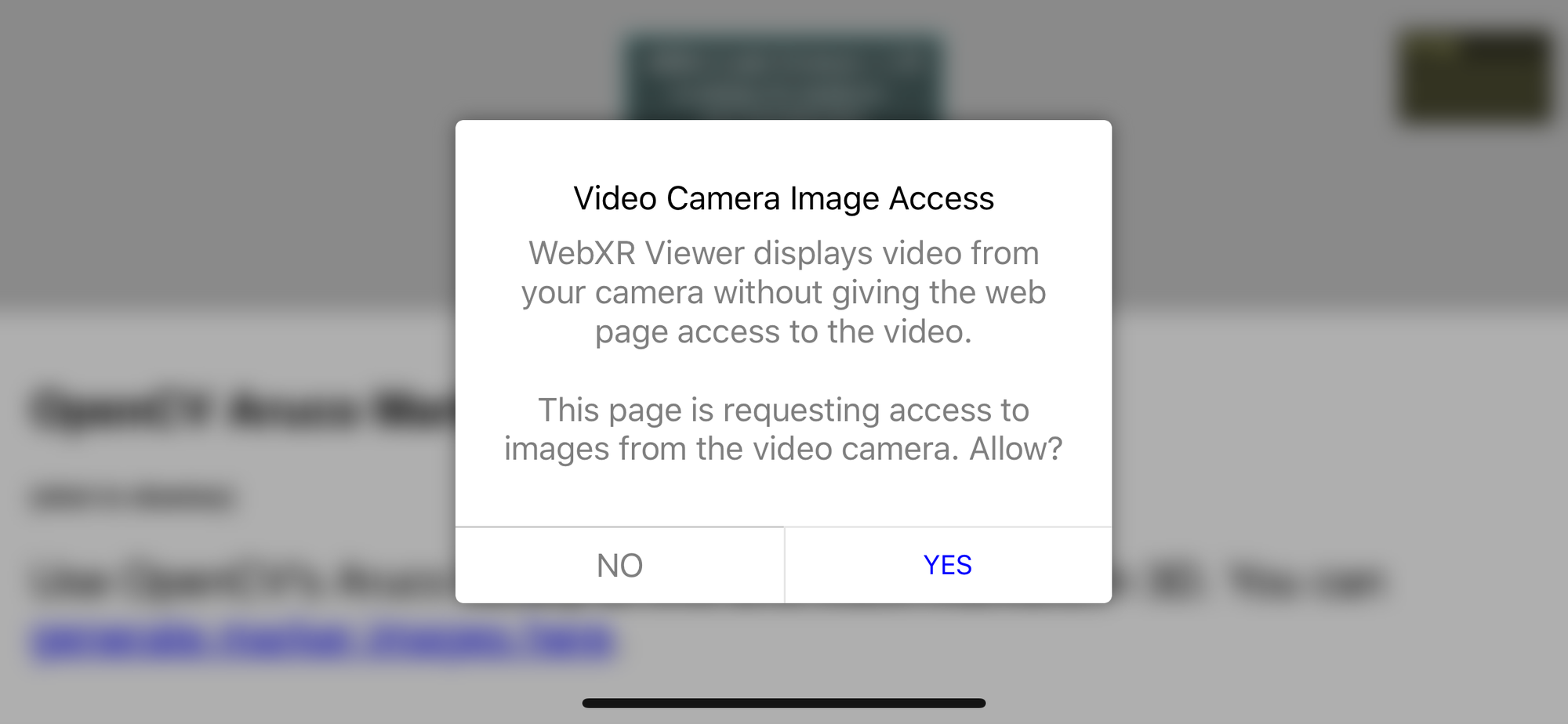
One interesting question we had to consider for this permissions dialog is the differentiation between the browser displaying the video, and the web page having access to the video frames. Phrasing this such that user’s understand what is being asked, and implementing the APIs such that users can toggle access on and off over time (for example) are challenges that will need to be addressed.
Examples to Illustrate the API
The color detection example above relied on just the first of the three requirements mentioned above: efficient video access. Because that example simply looks at the pixels and doesn’t use any spatial information (such as the pose or focal length of the camera), it doesn’t need to know those camera details. It’s easy to think of a variety of simple computer vision and image processing techniques that only need this limited information.
An collection of more complex examples can be found in the documentation for the Web Assembly version of OpenCV. We used one of their examples, face detection, as the basis for a second sample, one that is more complex than the simple color detector above, but still only relies on access to the video frames. Face detection algorithms typically use some form of template matching to find faces in an image, and return the bounding box (in 2D) of the detected faces.
You can run the example in the WebXR Viewer, or in any browser supporting WebRTC here.

You will notice a few things if you run the sample. Clicking on the graph in the upper right, you will see that the graphics speed (FPS) is likely higher than the computer vision speed (CV fps), which is possible because the face detector is running asynchronously in a Web Worker. Because the vision processing is asynchronous and can be slower than the rendering, the bounding boxes around detected faces lag a little behind the video. However, because it is asynchronous, we are not constrained to use algorithms that can run in real time, once per frame: if you hold a picture with many faces in front of the camera, the speed will drop, but the graphics speed will hold steady.
An obvious problem with this approach is that in a moving scene, if the analysis takes too long, the bounding boxes we get will not correspond to what’s in the scene when the application receives them from the Web Worker. Correcting for this latency is difficult because the bounding boxes are 2D, not 3D: we don’t know where the faces are relative to the viewer, just where they appeared in 2D in the video image.
By leveraging the second and third properties listed above (intrinsic and extrinsic information about the camera), we can do better. Knowing the intrinsic properties of the camera (it’s field of view, and so on), computer vision algorithms can determine where something is in 3D relative to the camera. Knowing the extrinsic properties of the camera (where it is in the world), allows us to then know where those things are in 3D world coordinates.
To leverage this information when not running the computer vision synchronously with the rendering, we need one more thing: a way to relate the pose camera when the video frame was captured to the pose of the WebXR device. In general, the renderer and camera many not run at the same speeds (for example, the HTC Vive displays at 90Hz, but its front-facing camera runs at 60Hz), and even when they do (such as in ARKit), by the time the asynchronous computer vision processing is finished, the camera will have moved. XR systems (like Hololens, ARCore and ARKit) do not guarantee that world coordinates are stable over time. In practice, this means that from one rendering frame to the next, the coordinate system in which the positions of the device and any Anchors in the world are reported may change, so the extrinsic camera parameters from one frame may not be valid the next frame.
We solve this problem by expressing the camera’s extrinsic pose relative to an Anchor in the scene, not in world coordinates: by knowing the pose of the camera relative to some Anchor when a video frame is captured, at some point in the future we can find the Anchor in world coordinates, and compute where things relative to that camera are in the current world coordinates.
To explore this idea we used another OpenCV example, the Aruco marker tracker for small black and white markers. Each computer vision frame, we use OpenCV to detect the pose of any visible markers relative to the camera. When we receive this information back from the Web Worker, we can determine the pose of each marker relative to the Anchor used for the extrinsic pose of the camera, and in turn compute the location of each marker in the current world coordinates.
Given a marker pose in world coordinates, the first time we see a specific Aruco marker we create an new Anchor for it. When we get an updated pose for the marker in subsequent frames, we compute a offset from the maker’s Anchor, and use that to position the content correctly near the Anchor each time the scene is rendered.

As you can see in the video, this has some nice properties. When the markers are not visible (either because they are occluded or because the camera is moving fast and the video is blurry), the boxes drawn on the markers are still tracked in the world, because they are attached to Anchors which are updated each frame by the platform. Since we have the accurate camera properties, the real-world pose of each cube is relatively accurate, so the cubes appear to be stable in the world. Even when the marker tracker is running very slowly, the results acceptable.
What’s Next?
The specific API and approach we have taken is by no means a firm proposal for how this might be implemented in practice, but rather a feasibility demonstration. While the cameras attached to WebXR displays could be exposed directly through the WebXR APIs, as we have done here, there are existing web APIs that it could be extended to support much of what is needed.
Two components will probably need to be exposed through the WebXR APIs: the physical configuration of the display, and a way of relating the pose of the camera frames to the device pose. The pose of each camera attached to a WebXR display (part of the extrinsic parameters mentioned above) are particular to WebXR; AR and VR displays will have this information precisely calibrated and available to the browser, but other computing devices may not. And to determine where the camera was looking when a frame was captured (in the coordinate system of the device) will require knowing the precise relationship between the timestamps of the video frame and the WebXR API poses, something not currently possible inside the web page.
A minimal approach might only require the WebXR Device API to expose the spatial configuration of the cameras on the device, some way to synchronize camera and devices poses, and pointers to instances of the camera devices implemented via an extended version of the MediaStream Image Capture API mentioned above.
Some additional functionality may be required to ensure the camera implementations are efficient enough. For example, video frames are large, and each additional copy or format conversion of a frame adds latency and wastes battery and processing time, precious commodities when doing high performance 3D graphics on mobile devices. Extensions to the MediaStream APIs could support returning video in its native format, and to fire events when new frames are ready to reduce latency and unnecessary polling. These ideas were explored in a proposed Media Capture Stream with Worker extension to the MediaStream API. While work on that proposal was discontinued last year, it may be worth revisiting. Similarly, the extentions to the MediaTrackSettings dictionary proposed as part of the MediaStream Capture Depth Stream Extensions included the intrinsic properties of the camera, including focal length, principal point and distortion coefficients.
Regardless of the approach used, it seems clear that supporting high performance, custom computer vision in web pages as part of WebXR is possible. Such support would open the door to a wide variety of cross-platform AR applications that would otherwise be difficult or impossible to create.
We welcome your thoughts on these ideas, and encourage you to try them yourself with the WebXR Viewer and webxr-polyfill, or to join the Immersive Web Community and help define these (and other) aspects of the future of AR and VR on the web.
I want to thank the people who have contributed to this project, especially Roberto Garrido who implemented these capabilities in the WebXR Viewer and worked on the modifications to the webxr-polyfill with me. Anssi Kostiainen and Ningxin Hu (Intel), Chia-hung Tai (formerly at Mozilla) and Rob Manson have all pointed me at the draft extensions to the MediaStream APIs at different times over the past few years; Ningxin has be very generous with ideas on how to fully integrate these with WebXR, and in helping me getting OpenCV working (including modifying the opencv.js build scripts to include the Aruco marker tracker). Iker Jamardo at Google demonstrated that it was feasible to inject video frames into the wkWebView, and provided other implementation feedback. I had a number of conversations with him about these ideas, as well as with Josh Marinacci, Trevor F. Smith, Kip Gilbert, Lars Bergstrom and Anselm Hook at Mozilla, all of whom provided input and inspiration. Members of the Immersive Web Community also provided early feedback to these ideas, and it was during discussions last year that the idea of using timestamps and anchors to deal with fully asynchronous video originated.