
A Great Demo, But Not WebAR (yet)
As part of GoogleIO this past week, Google released some sample code on github for a little demo that exposes Tango's sensing into Chromium.
At the top of the README it says:
This project's goal is to provide an initial implementation of a possible Augmented Reality (AR) API for the Web on top of Chromium. The initial prototype is built on top of the Tango platform for Android by Google. Maybe, more platforms will be supported in the future. There is a precompiled and working prototype you can use right away along with documentation of the APIs and some examples. There is also a tutorial on how to build your own version of modified Chromium with the WebAR APIs in it.
A major objective of this project is to get a conversation going on the subject of how to provide Augmented Reality capabilities to the web: WebAR.
Since I've been working on bringing AR to the web for quite a few years[1], and have been giving talks on my ideas for WebAR since last December, I'm happy to see Google release this and bring attention to WebAR. This prototype demonstrates that it is possible to do platform-accelerated AR in a mobile web browser, and gives us something tangible to talk about.
I will also note that the README also says:
Defining how a web standard will look like is a complex conversation. All the code and proposals in this project are not meant to be the definitive implementations of AR capabilities for the web, but some prototypes you can play around with at your own risk and have some starting point to build upon.
So, with that in mind, while this Tango project is a very nice tech demo, how does it measure up as a proposal for WebAR?
TL;DR: As a demonstration of exposing Tango tracking into Javascript, it's great. As a proposal for WebAR, starting with WebVR is a good idea, but the proposed extensions go about this the wrong way by requiring the application to render the view of reality inside the webpage.
From WebVR to WebAR
First and foremost, the idea of extending WebVR to support AR is a good one, and I agree that WebVR is the right starting point for WebAR[2]. WebVR has already "solved" the problem of doing real-time, high-performance 3D VR rendering in a web browser.
For those not familiar with WebVR, it integrates native VR SDK's (Oculus, SteamVR, etc.) into web browsers, and presents them in to web developers in a uniform way. A WebVR web application uses WebGL to render frames for a VR display based on data from the underlying VR tracking and interaction devices, using whatever web frameworks the developer wants (threejs is a common 3D library that works well with WebvR). WebVR works amazingly well: if you haven't looked at high performance 3D on the web in a while, you'll should try it out. Tools like A-Frame make it easy to create simple VR experiences that you can host on your own website (WebVR isn't officially released in most browsers, but should be this year: if you haven't tried it, download Nightly or Dev Edition of the Firefox Betas and try out the A-Frame demos).
The WebVR architecture is pretty simple, at a conceptual level. After initializing WebVR, your webpage can submit frames (rendered in a WebGL canvas) to the WebVR implementation.
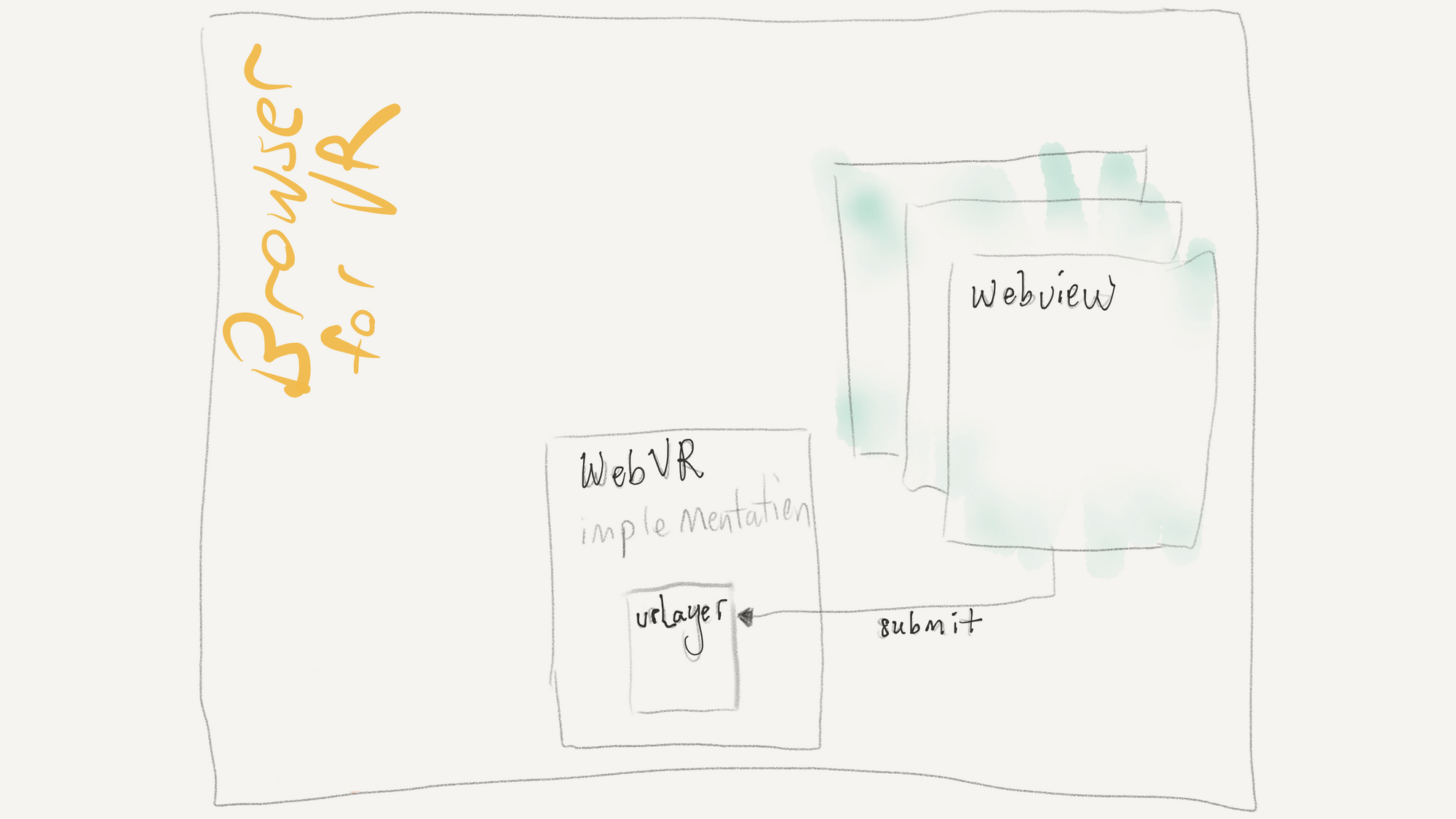
The browser takes care of calling the web pages at the right framerate, with the current VR device data, and passing the submitted frames to the underlying SDK's, which in turn takes care of rendering them on the VR display.
The Right WebAR Extension to WebVR?
So, the question is, what's the right way to extend WebVR to support AR. We won't have a platform-accelerated prototype of WebAR at Mozilla until later this year, but have been working on this problem, and exploring what might be possible with web-based AR using the Argon4 browser with a combination of argon.js and A-Frame[3].
What this google code does is pretty straightforward: use the Tango spatial tracker as the VR tracker (good), make the point cloud data available to the app if it wants it, and provides the video to the web app in a texture for rendering in the background of the web page. On the surface, this seems pretty reasonable. If you look at how people have thought about AR web applications up to now, this follows that model: get the video (usually via WebRTC's getUserMedia), do some computer vision on it (perhaps via a library like JSARToolkit) and render the video with some 3D graphics using a WebGL canvas.
However, AR on the web has been done this way because it was the only way it could be done. And this approach presents a number of problems in the context of the web, which I'll split into Platform Independence, Performance, and Privacy.
Platform Independence
A primary goal of a WebAPI like this (one that WebVR handles reasonably well) should be to allow web applications to run across a wide variety of different sorts of "user agents" (web browsers or other programs that display web content), letting developers create applications that users can consume on their preferred platform.
The tight coupling to the platform is the first problem with this approach to creating Web-based AR. By forcing the application to deal with rendering video from the camera, you limit applications created this way to platforms that create AR by putting graphics on a top of video from simple camera; if a different setup is used, applications would need to deal with each different platform configuration.
While handheld devices are the primary way people will experience AR/MR right now, more promising approaches use different approaches. Microsoft's Hololens (and other displays like Daqri's Smart Helmet) are optically transparent: there is no video to render (and no need to access the camera at all). Worse, other systems (such as video-mixed displays that combine video with depth data to render video from the user's actual eye point) will need to handle presenting "the view of reality" to the software themselves, so an API that hands video into a web app and expects it to render it is impractical.
Beyond video, the depth data is presented to the application in a way that is coupled to the underlying Tango implementation. Windows Holographic uses similar depth sensors and SLAM-based reconstruction, but presents the data to the programmer in a different form. Apple is rumored to be working with similar technology (having bought multiple companies over the years that develop hardware and software of this sort), and may use one of these representations, or opt for something entirely different. Relatively speaking, this is probably minor, since we don't yet have a good common format; it may be that each platform will present the data differently, or the underlying WebAR implementation will need to convert between representations. Time will tell.
Performance
Even if you are willing to ignore platform independence, passing the video into the application (in a WebGL texture or Javascript buffer) and having the application render it eliminates any opportunities for platform-specific optimizations.
What if your hardware can efficiently preload video into the GPU and composite it with another render buffer on-the-fly during rendering, without "rendering" that video as a texture to a polygon? Or if you could leverage techniques like WebVR's Time Warp or Space Warp to display the very latest video frames at rendering time, instead of the video frame that was available when the application started rendering?
Delegating rendering of reality to the application eliminates any of these opportunities. And, as modern VR SDK's have demonstrated, aggressive optimizations will be needed if we try using video-mixed AR in head-worn displays. With video-mixed AR, the latency from when a camera begins to capture a video frame in its sensors until it is available for rendering on the screen is too large (by itself) for use in an HMD without predictive rendering of some form.
Privacy
While not often discussed in the context of AR API's (unfortunately), any proposal for WebAR should consider how to give user's control over their privacy while getting the benefits of AR.
The approach used in this sample, if implemented in a real web browser, would likely ask if the web application could access the camera (and perhaps ask about the depth data too), following the approach of current web APIs. That's all well and good, but this architecture would mean that users only have two choices: don't use AR applications at all, or give incredibly detailed information (essentially, a 3D texture-mapped model of the space you are in, the people you are with, etc.) to every AR web page.
If you think about AR as "rendering graphics on top of video", you might imagine that all AR applications need this information to function. But why? If the underlying platform can take care of presenting a view of reality, and the platform SDK's like Tango are already doing the complex tracking and sensing needed for AR, could AR applications get by with less access?
This is an especially important question on the web, because unlike native applications, which tend to be intentionally downloaded ahead of time from an app store of some sort, a user may need to grant access to sensitive data on-the-fly as they follow a link to an unknown site.
Even if a user knows which site they are visiting, a good WebAR implementation should allow them to leverage the power of AR without giving applications this incredibly detailed and possibly sensitive data. The approach proposed here is all or nothing: let the app build a 3D texture mapped model of your space, which it could send off to the cloud and use for whatever purpose it might want, or don't use AR web pages.
Can we do better?
Yes, we can.
The history of the Argon project is instructive, and shows how we arrived at an architecture that addresses these concerns. Argon1[4]
wasn't a standard web browser, using an AR-specific derivative of KML (the markup used by Google Earth and Google Maps) we called KARML. With Argon2 we switched to a more traditional web browser model, and took the simple approach (akin to what's proposed here) of passing the underlying sensor/tracking data directly into the web apps so they could render as they wanted.
But as we started thinking about porting to other sorts of platforms (e.g., see-through head-worn displays, or projection displays[5] and developed some more sophisticated ideas for delivering AR on the web (e.g., how to support multiple simultaneous applications and custom representations of reality, discussed below), we began to define a more platform-independent set of abstractions during the development of Argon3[5]. These abstractions formed the basis for the argon.js framework and the implementation of the current Argon4 browser (led by a PhD student in my lab, Gheric Speiginer).
Building on the ideas developed in Argon4, here is what an architecture for WebAR might look like. The key take-away from this diagram is that presentation of the view of reality (in this case, the video) is handled inside the browser, and information is passed to the web page only if needed by the web application (and approved by the user). (In Argon, we are limited to using the built-in WebViews, so we render the reality in a separate web page behind the AR pages, but with a true implementation of WebAR, this compositing can be handled correctly and efficiently inside the browser engine itself.)
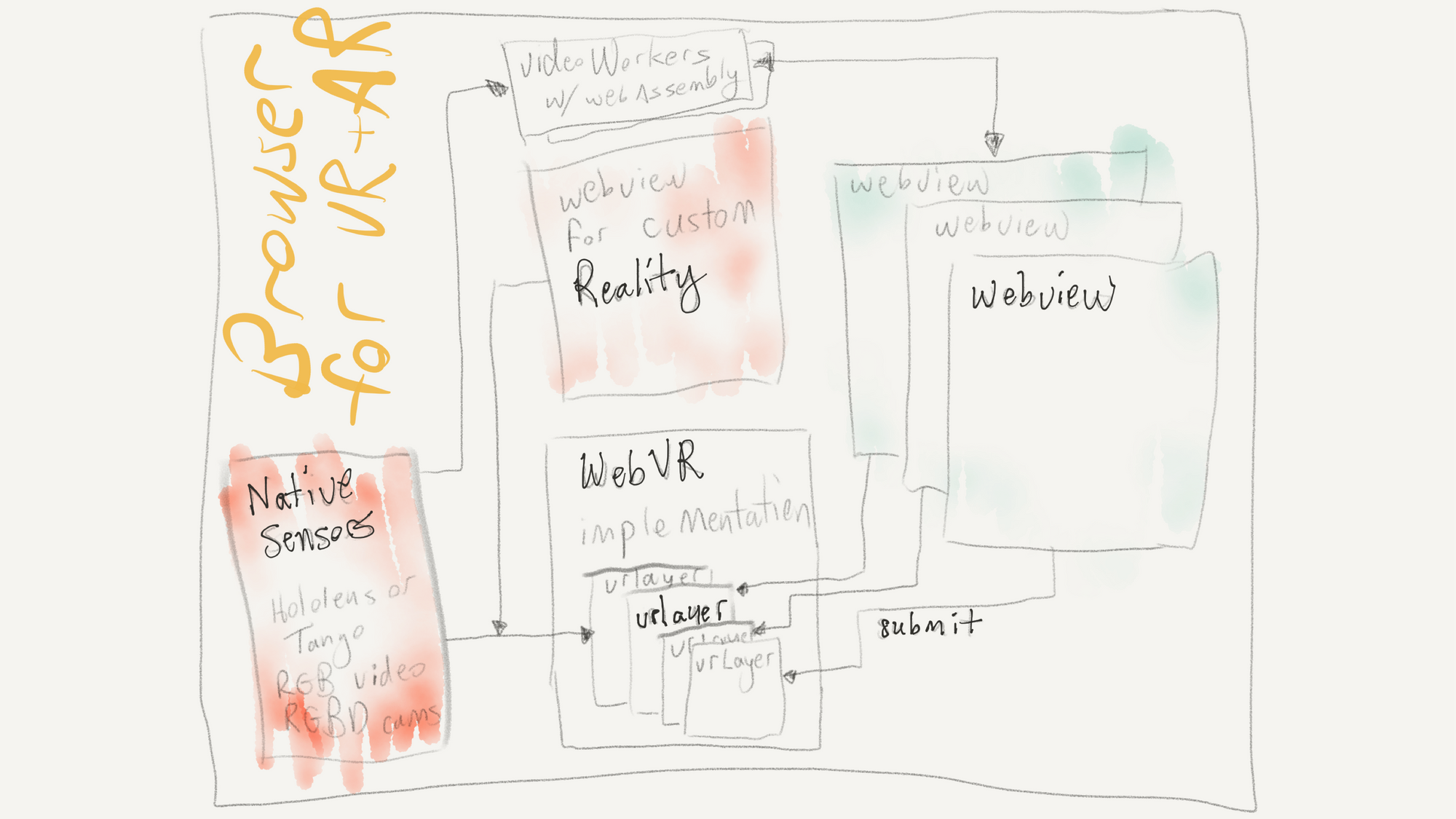
There are multiple things happening in this diagram.
The core idea is to extend WebVR's layers to allow the browser itself to render a view of reality behind the application content. If we took this approach with this Tango implementation, the video texture (and associated rendering) could be completely removed from the application. As with WebVR, the application would know it's pose relative to the local space, and render it's 3D graphics appropriately. Whether (or if) the application has access to Tango's point cloud could be handled separately.
Some applications may want access to the video, for doing advanced rendering or custom computer vision. That should still be possible, and could be provided to the application synchronously with the WebAR render loop. In this Tango implementation, it's provided in a texture. In this diagram, I envisioned using Workers of some kind to receive and render video frames synchronously, but any similar approach (providing video frames in multiple forms, or combining browser-based vision processing with native processing via OpenCV or OpenVX) would work.
The key is that providing video (or other sensor data, such as point clouds or world meshes) to every web application is not an absolute requirement for WebAR. Perhaps an application could refuse to run without this data, or perhaps it could run with limited features (e.g., without the mesh, objects could only be placed on "the floor"; without video, shiny objects might not have pretty reflections of the world). But it should be possible to build WebAR applications that give user's the benefits of AR without requiring them to expose detailed sensing of the world around them to any and all web application developers.
Beyond Basic WebAR
While not central to this discussion, this architecture envisions that WebAR could then support many simultaneous web applications rendering at the same time. All of your AR content (from work, to games, to search, to social applications) could be mixed in your view, under your control (this pre-supposes new browser UIs that give users control of which, and how many, web apps are simultaneously displayed). We've taken this approach in our Argon4 browser, although we have not yet explored the UI issues it brings up.
This architecture also envisions browsers supporting multiple representations of reality, including "realities" created by application programmers, a feature we developed as part of argon.js. In the AR/MR community, we tend to focus on AR/MR as "mixing media with a user's view of the world around them", but a more practical definition is "mixing media with a user's view of the world". If someone has created an tour of Notre Dame Cathedral in Paris, can I experience the tour without visiting Paris? Could I show that tour to a class of school children studying Notre Dame? Why not allow the user to overlay that tour on some representation of the world, such as Goolge Streetview (if you visit Streetview, it combines their outdoor panoramas with user created panoramas inside the cathedral).
Or perhaps a synthetic view of the world could be generated from open data (such as Open Street Map data)? While not "the same as being there", giving user's control over how to experience "augmentations of reality" should be a goal of any implementation of AR on the web (just as WebVR experiences can be viewed in browsers without VR gear). In argon.js, we have examples of "realities" created with local live video, StreetView and sets of geolocated panoramic images. We're working on generating models of any part of the world (e.g., like the views generated by ViziCities project, building on sites like MapZen).
Moving Forward
The core idea presented here, that the presentation of the view of reality should be managed inside the browser, is an essential component of any future implementation of WebAR, and is missing from this tech demo.
This idea is essential if WebAR is going to enable developers to create AR applications that run across many platforms, achieve high performance while still providing the necessary flexibility developers will want, and give users the benefits of the Web ecosystem (especially choice of which user agent they use, and control over what information they share with web sites and web applications).
So, in summary, this Tango demo is a great first step, and demonstrates it is possible to implement WebAR. As a proposal for WebAR itself, it's also starting in the right place by building on WebVR, but the relationship between the underlying platform and how programmers present content over the user's view of reality needs to be rethought.
I look forward to this conversation continuing, and the work that will be happening over the coming year!
In 2009, we started the Argon project at Georgia Tech, and my students and I have released four versions of the Argon AR-capable web browser over the years, most recently Argon4 and the argon.js framework. Last November, I joined the Emerging Technologies group at Mozilla to work on WebAR. My most recent talk on WebAR was the keynote at Philly ETech 2017. I usually present using Argon4, using a mix of 2D and AR, my ETech slides are available to look at here, although they might need me talking through them to make the most sense. ↩︎
If you skim the W3C WebVR Spec Respository you'll see that many of us are also interested in taking this approach. ↩︎
I'll be blogging more on this soon! ↩︎
↩︎- ↩︎
- ↩︎
Great dissertation on how WebAR could evolve. I agree that the User Agent needs to handle more and only expose functionality as needed. I also agree that extending some of the functionalities of the WebVR API is the right way to go (like extending the VRLayer structures) and that the 3 pilars (platform independency, performance and privacy) are essential goals we all should pursue. The only issue this article should cover (in my opinion) is the important fact that the Chromium WebAR prototype lays a foundation to build many of the elements that are commented here. The WebVR specification is going through significant changes for its release version 2.0 that will affect many of these discussions. This is not an excuse to say that we cannot have conversations as where the WebAR API should evolve to. But my take is this: By exposing low level functionalities, we can have a conversation about possible API routes in a much meaningful way as many of the elements discussed here could be implemented using polyfills. Want a VRLayer that renders the camera? Want to check it feasability? With one of the main characteristics of JavaScript this is a possibility. Maybe not everything can be achieved, and when this time comes, the modifications to the UA can be proposed. But modifying the UA is not trivial and takes time, so my opinion is that proposals should be well thought. The current proposal is not perfect and is not meant to be, but I deeply think/hope it will unleash both a healthy conversation about the spec and also allow to start building experiences on top (as important as the spec is to start building use cases that might highlight needs in the spec itself).
I agree that we can experiment with polyfills. And, that others could experiment with these three pillars by taking the code and trying out different ideas for doing that. That would be great, I hope people do! We hope to add support for this into argon.js and do some of that work.
This Chromium demo, as "an AR extension for WebVR to spur discussions", is great: it creates the necessary infrastructure for experimenting with what one might want or need to do.
But, I was responding specifically to the API as a model for how WebAR should work, and things folks should think about when building on this work. The Chromium demo as "Proposal for WebAR" (which is what the README says, and what what people are therefore talking about) does not do that. The API "proposes", based on the methods and structure that is exposed, that WebAR should be based around the idea of sending video and sensor data into the web page for rendering, and I think this is a fundamentally wrong way to implement WebAR. And since the web page asked for a discussion of this as a proposal for WebAR, I discussed it that way. :)
You and I understand the tradeoffs on implementation approaches: we've chatted about them in the past. There are limitations by not giving the web page access to video (e.g., some graphical effects are impossible), so I can understand the desire to provide it. Not providing the video also limits ways things could be rendered in the page. But, this prototype could equally have rendered the video (and perhaps depth info) into the canvas inside the Chromium extension (before calling rAF).
I think the demo is great, as I said in the article. But I want people who use it and experiment with it to be thinking about these issues.
Enjoyed your blog as it raises the question of context. Why an XR experience should adapt to diverse user's context? It is something to consider in the design of such experiences.
Also, along representations of the world proposed through StreetView or OpenStreetMap, I would also consider Mapillary and the Mapillary API https://www.mapillary.com/d.... They have been very creative developing a Structure from Motion workflow (3D reconstruction from user generated 2D images of streets and cities) with OpenSfM https://github.com/mapillar.... That could count as another source of “realities” for argon.js - for which I also thank you very much!
Cheers!
Thanks for the pointer to Mapillary, I hadn't seen that, we'll check out. Looks like something we should support, and can make good use of!
Can you give me an example of what you are thinking about with respect to diverse user's context? I think adapting to different users to give them the best possible experience is probably a dream of most developers, but getting access to content to help with that adaptation is the challenge. What do you imagine?
Thanks for your question.
Well, for a start, we could imagine a sort of responsive adaptation to user’s context by getting more granular with the elements of a mixed reality experience. Again, going back to the Mapillary breach into computer vision, the second aspect of their approach (aside from structure from motion and point cloud creation) is semantic segmentation, « automatic tagging for each pixel ». The questions for me would be: what are the the elements (gestures, motions, sonic, visual features, etc.) at the core of a given experience? How could a web system (browser or else) learn from and adapt to those core elements? Which resources could this system deploy to render an appropriate view of reality following user’s choice and respecting the core elements of the XR app?
For example, the representation of reality could be extracted and generated from point cloud data from user generated geotagged photos. The web system would then be charged with matching the core elements of the mixed reality experience with this given reality. As in a continuum from VR to AR, the user could then control how dense and how close to real-time this reality is. Because, as you said in your blog post, this representation could also be a construct made of archives (e.g. StreetView). Also, building on the automatic semantic segmentation, some machine learning could help make the matching more adaptative and communicate to the user what is perceived from its context. Although, in the end, isn’t the user’s context up to the user to control and communicate?
I get what you are suggesting, that kind of adaptation is the sort of thing that has motivated folks doing adaptive computing (in Ubicomp, AR and so on) for years. The problem is, this kind of understanding of visual scene and the user's context is notoriously hard to get right, and when the system gets it wrong, it break the illusion ... badly. I think as this kind of scene understanding gets better, and we figure out what kinds of context actually matters, it'll be possible to do this sort of thing. I don't really see it happening any time soon, though.