
The AR Cloud will not be One Big Crowd-Sourced Map
Trevor Smith started a twitter thread pondering architectural alternatives to the idea of “One Big Map” for the so-called AR Cloud, it’s an interesting read (although getting all the replies might require some digging[1])
I've had a few initial conversations with @blairmacintyre about an alternative to AR cloud relocalization. Instead of One Big Map, the AR devices and the architectural elements cooperate to resolve precise poses for devices.
— Trevor Flowers 🌸🌸 (@TrevorFSmith) February 16, 2019
There’s a lot going on in this thread. As with all discussions of the AR cloud, there’s a segment of folks who can’t get see past the idea that “the AR cloud requires we scoop up data and build big maps.” I think the point of Trevor poking at this is to counter (or at least stir up discussion) of this.
AR Cloud Does Not Require Automated Data Collection
There are some fundamental things I disagree with about the premise that the AR Cloud will require automated data collection. Certainly, automated data collection is the most straightforward approach. It (conceptually) allows one company to control the persistence and relocalization workflow. And it might seem that the only way to ensure stable, consistent global persistence and sharing of data is to have everyone share one tracking infrastructure. There is an appeal to solving the whole problem in a self-contained way, which captures the imagination of enthusiasts and entrepreneurs.
But these arguments ignore the technical landscape that these systems will co-exist with. It’s very likely the underlying platforms will solve at least part of this problem, for example, perhaps offering precise geolocation in public areas. There are other fundamental issues I have, especially as they relate to personal privacy. For example, I do not believe that any representation of the features/structure in a space is inherently private and can’t be used to create a human-readable version of the map: if it can be used for relocalization in the space, then some Deep Learning (or other ML) system could conceivably extract structure from it, especially as the maps are updated over time.
Two Arguments Against These Concerns
There are two very different arguments I’ve had presented to me in response to the privacy concerns I have with automated crowd-sourced approaches.
The first argument is the “people can already take pictures and post them to social media without your permission, so this is no different.” This argument ignores the glaring difference between taking pictures with a mobile device, and automated data gathering. Taking pictures is an intentional act; taking a picture and posting it somewhere is an explicit activity. While different people and groups have different social norms about taking and posting pictures in other people’s spaces, these norms exist and mesh well with the intentionality of the actions. Pictures are also discrete, and if I don’t like a picture a friend posts on social media, I can ask them to remove it.
None of this is analogous to continuous data collection, where that data is thrown into a crowdsourced soup of the 3D structure of the world. The process is hidden, continuous, and automatic. If you want to cling to the picture-taking analogy, this is more like publicly live-streaming video (or a stream of individual pictures) then it is to posting individual pictures to social media (anyone remember the reaction to “Glassholes” filming what they were looking at?).
This data is likely to persist forever, too, in some form. The whole point of collecting this data is that it will be merged into a global maps. Once its integrated, and additional data is merged on top, getting it completely removed will be impossible. It’s out there.
The second argument is that we could control who can post information about spaces, limiting it to authorized people. For example, only property owners can post or give permission to post. But this idea is impractical and invasive.
Consider the simple example of a family living in an apartment. Who has permission to contribute to the map? The person who owns the apartment, or the family living there? Can the owner of the building turn on permissions without the concept of renters? What about when one family moves out and another in? What about members of the family. Do the teenage children automatically have permission? Can they authorize their friends, perhaps because they want (need) to have an AR experience together in the house?
How do we even detect precisely where we are in the world to a level of detail needed to query the hypothetical permission system unless we already have precise location? Without precise localization, we can’t differentiate between hallways and being “just inside the door”, or between apartments next to each other or above or below each other on separate floors.
More dangerously, all of this presupposes that anyone using AR is able and willing to associate themselves with a public, authenticated, permanent ID (conflicting with the many good reasons for desiring anonymity when dealing with technology). It also presupposes that people will be willing and able to do the work required to monitor and manage the spaces they own, to challenge others who improperly claim what is theirs, and so on. There is plenty of evidence showing people are unwilling to do even trivial, obviously important “technical housekeeping”, such as backing up their devices. Most users click through permission request without necessarily considering the implications of them; people share and reuse passwords. And on and on. Why would we assume people will deal with non-trivial, ephemeral tasks such as managing “virtual access” to their spaces?
Embrace Realistic, Complex Solutions
This is not really a new problem. Back in 2010 when we created the first version of the Argon AR-enabled web browser, we presented the browser in the context of a broader technical infrastructure, which included the idea of layers of world information presented by a collection of public and private tracking and infrastructure services. (Our first publication[2]on the system didn’t include this image, but it was on the KHARMA documentation site.)
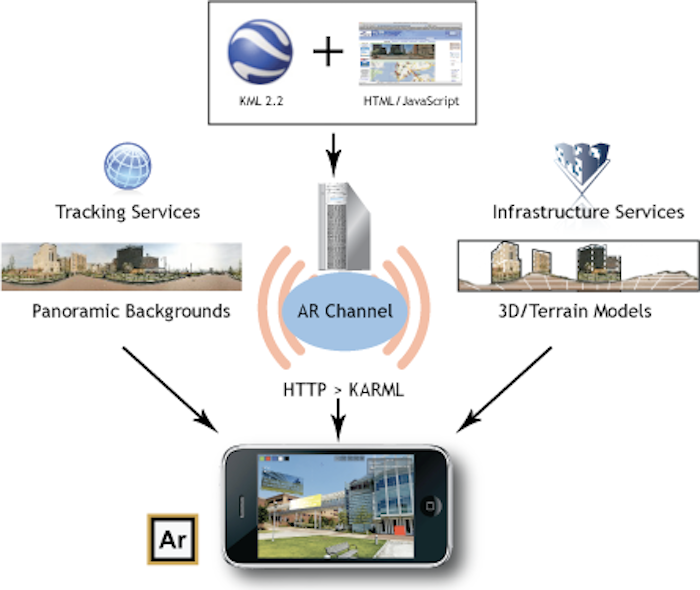
When I think about global localization these days, I still tend to combine multiple elements:
- baseline global localization using controlled, curated and managed data that is restricted to public spaces. Maps (or other base data) are explicitly managed, to ensure they only exist in public space (e.g., streets) or spaces where the verified owners have given permission to be included (e.g., malls, airports, museums).
- private data clouds created on a per device, or per user, or even per organization, basis. These clouds can be linked to the global maps for that user when they move between public and private spaces (e.g., I could share my cloud data between all my devices like I share my Apple Messages or Firefox bookmarks).
- the ability for people to share local maps with others on-demand (with or without linking them to the full map) to facilitate local co-located experiences
Most of the so-called AR Cloud mapping solutions being developed will work quite well to create private data clouds instead of global clouds. Some, like 6d.ai, are designed to do this.
With such a setup, when my collection of local maps is linked to the global map, I can localize globally within my map; I know my geoposition and geoorientation precisely, without contributing data to “One Big Cloud”.
Hololens and ML1 (the two major AR HMD’s right now) both create and save representations of spaces they are used in; ARKit allows maps to be shared and re-used; Google’s Cloud Anchors support local maps. All of these create spaces without leveraging global localization, right now. But it’s pretty easy to see that if the underlying platform could precisely localize itself (globally), hopefully only while in a public space, it would be relatively easy to set up a relationship between global and local coordinate frames, and thus know the precise global pose of the device when inside a map that’s been global localized.
Clearly, this approach isn’t as sexy as “The One True Map”, and has some limitations right now, when most AR is smart-phone-based and (thus) ephemeral. On a phone, I’m unlikely to be “doing AR continuously” as I walk from the street, through a building and up to my office, so the private AR map in my office or lab is unlikely to be linked to the global map.
But this is a near term problem, and can be solved.
Privacy and Automatically Crowd-Sourced Maps
I feel strongly about avoiding automatically crowd-sourced global maps, because this tension between crowd-sourced and curated global maps is at the heart of very real privacy concerns with the AR Cloud.
Consider Google’s Global Localization (I talked about it in a recent post), which takes the approach of using private, curated data (Google’s Streetview images) as the basis of a global localization scheme (their so-called VPS). Collecting and maintaining such a database of imagery is a massive undertaking, and some people have voiced concerns about relying on proprietary data for such a fundamental capability. (The same concerns could be voiced about GPS, which is run by a few governments around the world and powers much of our mobile computing systems.)
Relying on such an curated approach has some very nice properties. The base data (geolocated images) is visible and human understandable. It’s relatively obvious what data is used, and existing processes (and policies and social norms) are in place to deal with conflicts over content in the images.
In some ways, the crowd-sourcing approach implies throwing up our hands on privacy, arguing that no small company can compete, so we need to crowdsource our own private versions of these global geolocated anchors in what is essentially an uncontrolled and haphazard manner. The results are then stored in private, opaque, non-decomposable, formats.
Step Back and Consider Using Open Data
Perhaps we should instead step back and ask how we could follow the traditions of the open web to accomplish something similar to Google’s VPS.
One direction might be to build on OpenStreetMap’s nascent effort to add panoramic images to its street data. If we take the long view, it should be possible to (slowly) enhance something like OSM to include the data needed for global localization. The social and curatorial properties of OSM are even better than Google’s StreetView. New data can be added, old data deleted or edited, by anyone who cares to do it, allowing problems to be fixed on the ground by motivated parties. (For example, I was doing a project at my kids’ school, so I fixed up the building models, paths and other data on their property in a few days.)
There might be other approaches that could be taken, too, that support global localization combined with local precision, without charging forward with approaches that have obvious privacy problems, just because they are possible right now.
As with many technologies, it is up to us to decide what kind of future we want. Do we want a future where we control our data, and preserve notions of privacy and liberty? Or do we want to contribute to a future as imagined in any number of dystopic novels, where a live, continuously updated 3D model of the world exists, one that is easily abused for surveillance by governments and companies? Do we want a future with no physical privacy, where global “mirror worlds” expose all aspects of our lives to anyone who cares to look?
These questions are not hypothetical. Today’s news is rife with stories about governments and companies (ab)using technology for their own gain, at the expense of the public. And once this particular genie is out of the bottle, it may be impossible to put it back in.
I miss storify.com as a way to collect and publish a twitter story.↩︎
MacIntyre, B., Hill, A., Rouzati, H., Gandy, M., & Davidson, B. (2011). The Argon AR Web Browser and standards-based AR application environment. In Mixed and Augmented Reality (ISMAR), 2011 10th IEEE International Symposium on (pp. 65–74). IEEE.↩︎